أبرز النقاط (Key Takeaways):
- إطلاق نموذجي DeepSeek V3.2 و V3.2-Speciale بقدرات تنافس أقوى أنظمة الذكاء الاصطناعي الغربية.
- الشركة تتبنى استراتيجية “الكفاءة” بدلاً من الحجم الضخم، معتمدة على آليات تدريب مبتكرة لتقليل التكلفة.
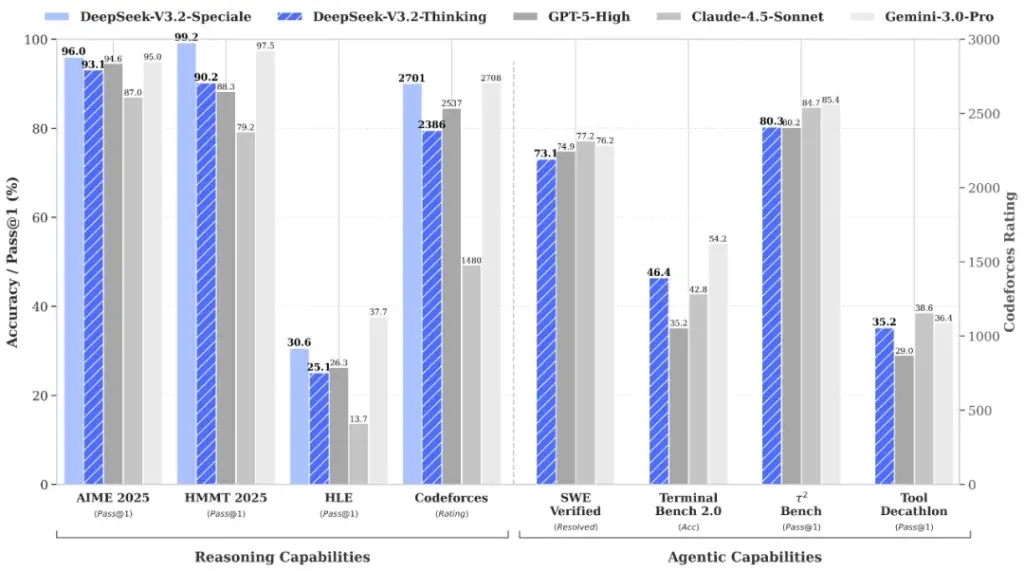
- نموذج V3.2-Speciale يتفوق على GPT-5 في المعايير الداخلية ويثبت جدارته في الأولمبياد الدولي للرياضيات.
بعد عام واحد فقط من إحداث هزة في الأسواق العالمية بنموذج فاجأ الجميع، تعود شركة “ديب سيك” (DeepSeek) الصينية مجدداً لتخلط الأوراق بإصدارين جديدين وطموحات تتجاوز الحدود.
أعلنت الشركة عن أحدث نماذجها مفتوحة المصدر: DeepSeek V3.2 و V3.2-Speciale، وسط تقارير تشير إلى قدرتها على مجاراة، بل وحتى التفوق على، أقوى أنظمة الذكاء الاصطناعي المتاحة حالياً، بما في ذلك “جي بي تي-5″ (GPT-5) من شركة OpenAI و”جيمناي 3 برو” (Gemini 3 Pro) من جوجل.
استراتيجية الكفاءة: الذكاء ليس بحاجة لموارد عملاقة
بدلاً من مطاردة مبدأ “الحجم الأكبر” بأي ثمن، تواصل DeepSeek الرهان على استراتيجية تعتمد على الكفاءة (Efficiency).
فبينما تعتمد المختبرات الأمريكية على مجموعات ضخمة من أحدث الرقاقات الإلكترونية، تجادل DeepSeek بأن نهج التدريب المحسن الخاص بها يمكن أن يقدم ذكاءً مماثلاً باستخدام عتاد أكثر سهولة في الوصول إليه.
ووفقاً للشركة، يتضمن النموذج القياسي ميزة “الاستدلال باستخدام الأدوات” (Tool-use Reasoning) بشكل أصلي، مما يعني أن المستخدمين يحصلون على قدرات تفكير منظمة دون الحاجة للتحويل إلى وضع استدلال مخصص.
نموذج V3.2-Speciale: وحش الاستدلال الجديد
يقع التركيز الأكبر في هذا الإطلاق على نسخة V3.2-Speciale. حيث تدعي الشركة أن هذا الإصدار قد تجاوز GPT-5 في المعايير الداخلية، ويقف على قدم المساواة مع Gemini 3 Pro في المهام التي تتطلب استدلالاً مكثفاً.
وكدليل على هذه القدرات، أشارت الشركة إلى النتائج القوية التي حققتها نماذجها في “الأولمبياد الدولي للرياضيات 2025” (International Mathematical Olympiad) و”الأولمبياد الدولي للمعلوماتية”، مؤكدة أن مشاركاتها النهائية منشورة ومتاحة للتدقيق العام.
السر التقني: ابتكارات خلف الكواليس
تُرجع DeepSeek هذه القفزة في الأداء إلى ابتكارين رئيسيين في هندسة النموذج:
- آلية الانتباه المتناثر المخصصة (Custom Sparse-Attention Mechanism): صممت خصيصاً لرفع كفاءة التعامل مع السياقات النصية الطويلة.
- توسيع خط أنابيب التعلم المعزز (Reinforcement Learning Pipeline): حيث تم تدريب النموذج على أكثر من 85,000 مهمة معقدة ومتعددة الخطوات، تم إنشاؤها بالكامل عبر نظام داخلي يُعرف بـ “توليف المهام الوكيلة” (Agentic Task Synthesis).
التوفر وكيفية التجربة
للراغبين في اختبار هذه القدرات، فإن نموذج V3.2 متاح بالفعل عبر موقع DeepSeek الإلكتروني، وتطبيقات الهاتف المحمول، وواجهة برمجة التطبيقات (API).
أما النسخة التجريبية الأكثر تقدماً V3.2-Speciale، فهي متاحة حصرياً عبر نقطة وصول مؤقتة للـ API، ومن المقرر إزالتها بعد 15 ديسمبر 2025. تعمل هذه النسخة حالياً كمحرك للاستدلال فقط (Reasoning-only Engine)، ولا تدعم استدعاء الأدوات.
الخاتمة: ضغط على عمالقة الصناعة
بينما ستكون الاختبارات المستقلة (Independent Benchmarking) هي الحكم النهائي لتحديد موقع هذه الأنظمة مقارنة بالعمالقة، فإن هناك حقيقة تتضح يوماً بعد يوم: DeepSeek عازمة على إثبات أن الذكاء الاصطناعي من الطراز الأول لا يتطلب بالضرورة تكلفة باهظة.
هذه الرسالة بحد ذاتها تضع ضغوطاً هائلة على بقية الصناعة لإعادة التفكير في ما هو ممكن، وما هو ضروري حقاً للبقاء في دائرة المنافسة.
📡 للمزيد من التغطيات اليومية، استكشف قسم الأخبار عبر موقعنا.
ابقَ دائماً في قلب الحدث التقني! 🔍
انضم الآن إلى نخبة متابعينا على تيليجرام و واتساب لتصلك أهم الأخبار والحصريات فور حدوثها! 💡