


شهدت منصة Grok AI قفزة كبيرة في الأداء مع الإصدار الجديد Grok 4، حيث تفوّق بشكل ملحوظ على الإصدار السابق Grok 3، واقترب من النماذج الرائدة مثل Gemini 2.5 Pro وClaude، وذلك بحسب نتائج أحدث اختبارات LMArena.ai.
تحسينات كبيرة في الأداء والترتيب العالمي
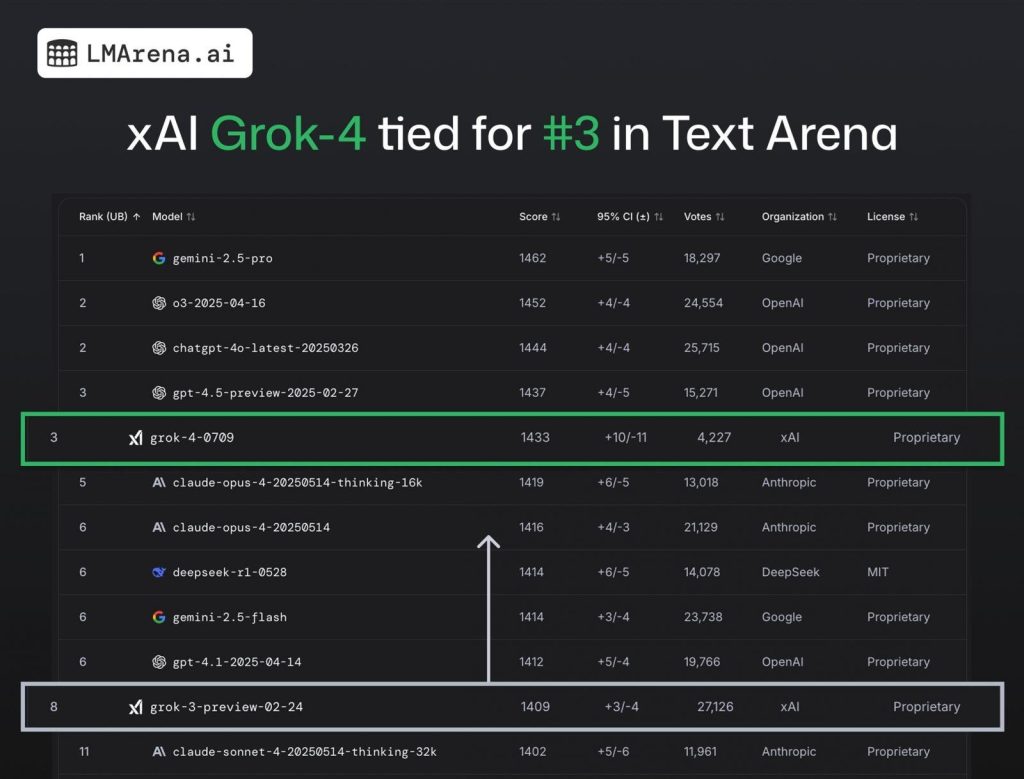
أظهرت منصة LMArena.ai، المتخصصة في تقييم نماذج الذكاء الاصطناعي عبر اختبارات مجتمعية مفتوحة، أن Grok 4 API (بالرمز: grok-4-0709) حصل على أكثر من 4000 تصويت من المجتمع، واحتل المركز الثالث في تصنيف Text Arena العام. هذا يمثل نقلة نوعية مقارنة بـ Grok 3، الذي جاء في المركز الثامن سابقًا.
نتائج اختبارات Grok 4
تم اختبار Grok 4 عبر مجموعة واسعة من المجالات الواقعية، وشملت التقييمات:
- الرياضيات: المركز الأول
- البرمجة: المركز الثاني
- الكتابة الإبداعية: المركز الثاني
- اتباع التعليمات: المركز الثاني
- التحديات المعقدة: المركز الثالث
هذه النتائج تعكس قدرة النموذج على التعامل مع مهام متنوعة تتطلب مهارات منطقية وتحليلية وابتكارية.
الفرق بين Grok 4 وGrok 4 Heavy
يجدر التنويه أن الاختبارات أُجريت على النسخة الأساسية Grok 4، وليست النسخة الأثقل Grok 4 Heavy، والتي يُتوقع أن تكون أفضل أداءً بفضل استخدامها تقنيات متعددة الوكلاء لتحليل ومقارنة النتائج. حتى الآن، Grok 4 Heavy غير متوفر عبر واجهة برمجة التطبيقات (API)، لذلك لم يُختبر بعد بنفس السياق.
Gemini 2.5 Pro وClaude يتفوقان في البرمجة… حاليًا
رغم تفوق Grok 4 في البرمجة بالمركز الثاني، إلا أن Gemini 2.5 Pro وClaude لا يزالان الأفضل حاليًا في هذا المجال. ومع ذلك، قد يتغير هذا قريبًا مع إطلاق نموذج جديد من xAI يحمل اسم Grok 4 Code.
النموذج القادم سيكون مخصصًا بالكامل لمهام البرمجة، ومن المتوقع أن يتضمن واجهة سطر أوامر (CLI)، شبيهة بما توفره نماذج مثل Gemini CLI وClaude Code.
📡 لمزيد من التحديثات اليومية، تفضل بزيارة قسم الأخبار على موقعنا.
ابقَ في صدارة المشهد التقني! 🔍
انضم إلى مجتمعنا على تيليغرام لتصلك أبرز الأخبار أولاً بأول! 💡








ابدأ المناقشة في forum.mjbtechtips.com